
tf-yarn is a Python library we have built at Criteo for training TensorFlow models on a YARN cluster.
It supports running on one worker or on multiple workers with different distribution strategies, it can run on CPUs or GPUs and also runs with the recently added standalone client mode, and this with just a few lines of code.
Its API provides an easy entry point for working with Estimators. Keras is currently supported via the model_to_estimator conversion function, and low-level distributed TensorFlow via standalone client mode API. Please refer to the examples for some code samples.
We start by presenting a brief summary of the core distributed TensorFlow concept. Those concepts are essential to understand the functioning of the building blocks on which the library relies. We will then review prior work, the reasons why we created a new library, and how tf-yarn has been implemented. In the end, we will cover some interesting issues we encountered during our journey and how we solved them.
Distributed TensorFlow
Here you’ll find more about the ParameterServerStrategy, as it is the distribution strategy activated by default when training Estimators on multiple nodes.
Distributed TensorFlow operates in terms of tasks. A task has a type which defines its purpose in the distributed TensorFlow cluster:
workertasks headed by thechiefdoing model trainingchieftask additionally handling checkpoints, saving/restoring the model, etc.pstasks (aka parameter servers) storing the model itself. These tasks typically do not compute anything. Their sole purpose is serving the model variablesevaluatortask periodically evaluating the model from the saved checkpoint
The types of tasks can depend on the distribution strategy, for example, pstasks are only used by ParameterServerStrategy. The following picture presents an example of a cluster setup with 2 workers, 1 chief, 1 ps and 1 evaluator.
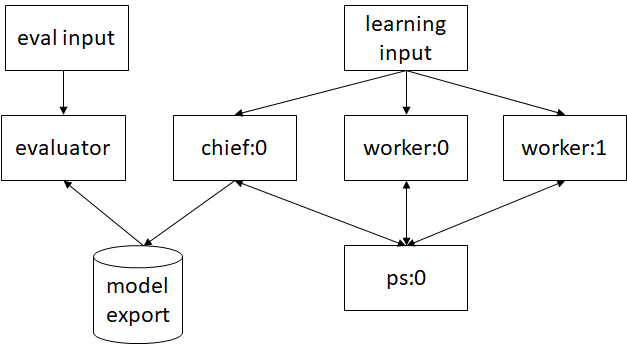
The cluster is defined by a ClusterSpec, a mapping from task types to their associated network addresses. For instance, for the above example, it looks like that:
{
"chief": ["chief.example.com:2125"],
"worker": ["worker0.example.com:6784",
"worker1.example.com:6475"],
"ps": ["ps0.example.com:7419"],
"evaluator": ["evaluator.example.com:8347"]
}
Starting a task in the cluster requires a ClusterSpec. This means that the spec should be fully known before starting any of the tasks.
Once the cluster is known, we need to export the ClusterSpec through the TF_CONFIG environment variable and start the TensorFlow server on each container.
Then we can run the train-and-evaluate function on each container.
We just launch the same function as in local training mode, TensorFlow will automatically detect that we have set up a ClusterSpec and start a distributed learning.
You can find more information about distributed Tensorflow here and about distributed training Estimators here.
Prior work
The problem of integrating TensorFlow into the Hadoop ecosystem is by no means new. We have evaluated two solutions at the beginning of 2018 were TensorFlowOnSpark open sourced by Yahoo in early 2017, and TensorFlowOnYARN aka TOY developed by Intel as part of their Deep Learning on Hadoop effort.
TensorFlowOnSpark
Perhaps, unsurprisingly, TensorFlowOnSpark uses PySpark to implement both distributed training and inference of TensorFlow models. TensorFlowOnSpark is flexible and supports multiple data ingestion mechanisms (Readers & QueueRunners, Dataset, PySpark RDD). It is also agnostic wrt the TensorFlow API used to define a model and will work with both “raw” models and Estimators. Finally, TensorFlowOnSpark provides an API for doing inference of the trained models.
TensorFlowOnSpark strives to minimize the amount of code needed for distributing existing TensorFlow applications. In our experience, the migration is indeed pretty straightforward.
The problem with TensorFlowOnSpark, as the name indicates, is that it is based on the Spark execution model. In Spark, each task is independent of each other and can be retried independently. This works perfectly fine for large scale Data Processing with petabytes of Data but doesn’t fit well with Deep Learning frameworks which rely on a completely different execution workflow, as the tasks are started once and then rely on extensive communication among each other. As Spark’s execution model didn’t fit our needs we needed to turn to other solutions.
In 2018, Databricks started a new initiative called project Hydrogen to fix the Spark execution model and enable Deep Learning frameworks to be executed on Spark. The relevant Jira ticket is still in progress.
TensorFlowOnYARN
Unlike TensorFlowOnSpark, TensorFlowOnYARN directly integrates with YARN by implementing an application master (AM). The job of the AM is to reserve a TensorFlow cluster with a specified number of workers and parameter servers and to spawn a distributed TensorFlow server on each of the containers. Once the cluster is up, the user launches a distributed TensorFlow training using the ClusterSpec provided by the AM.
Sadly, the development of TensorFlowOnYARN stopped at the proof-of-concept stage. The implementation requires recompiling TensorFlow with a custom patch exposing some of its internals to the Java runtime via JNI. The patch has been written for TensorFlow 1.0 and does not apply cleanly to more recent versions.
The master version of the project did not compile. The documentation was
largely missing, and the developers were mute about the future for this project. As much as we liked the ideas behind TensorFlowOnYARN we could not use it.
Reinventing the wheel
At this point, it seemed inevitable that we needed to write a new TensorFlow/YARN integration library from scratch. What should this library look like? What do we expect from it? In which way should it be different from existing projects?
- First and foremost, it should be a Python library in order to eliminate the need for crossing the language barrier both for the developers and the users;
- It should integrate with YARN directly in the same way as TensorFlowOnYARN. This would reduce the possible points of failure, simplify debugging — we had our share of debugging cryptic PySpark error messages — and allow to tailor the UX specifically for TensorFlow;
- Finally, it should provide a minimal API which is simple yet flexible enough to handle various training scenarios: single-/multi-node, CPU-only/mixed CPU-GPU.
In September 2018, LinkedIn published a similar solution to run TensorFlow on YARN with TonY. As we had already started working on tf-yarn and it worked well for us, we continued working on our own solution.
Today TonY supports more use cases, for instance, the integration with PyTorch. It is fully Java-based and handles the YARN integration directly with the YARN API.
The focus of tf-yarn is to make things simple. We feel that a fully Python-based solution allows easier integration with TensorFlow and allows providing some helpers libraries.
Two examples:
- Packaging, for instance, can be handled and integrated fully with Python (See packaging code with pex which also applies to tf-yarn).
- We used the Skein library to have a clean Python API for YARN container allocation with support for multiple Hadoop versions.
Getting TensorFlow to work on YARN
Now let’s have a look at how we integrated TensorFlow with YARN. On our Hadoop cluster, we first need to ask YARN to allocate the number of containers we want. Then we can reserve a TCP port for the TensorFlow server on each container, communicate it to all containers and assemble the ClusterSpec as described before.
tf-yarn uses Skein for the interactions with the YARN cluster. Skein is a Python library which takes care of all of the YARN heavy-lifting and allows to easily deploy Python applications on YARN.
This brings in a clean layer of abstraction for separating container allocation from interacting with TensorFlow. Also, it makes tf-yarn independent of different Hadoop cluster versions (Hadoop 2/Hadoop 3).
Skein comes with a key/value store (kv store) that is used to announce the host/port pairs (aka socket address) to all containers.
Having been among the early adopters, we had the opportunity to provide feedback and contribute bugfixes and features we found lacking. Thanks to the authors of Skein for their help.
Here is an example of how to use Skein’s API to allocate YARN containers:
spec = skein.ApplicationSpec(
[skein.Service(
script="echo 'Hello World!'",
resources=skein.model.Resources(memory="2 GiB", vcores=2)
)]
)
with skein.Client() as client:
app = client.submit_and_connect(spec)
We can easily specify the resources we want to allocate to each container and the script we want to execute. The Python script we need to execute on each allocated container looks like this:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.bind(("", 0))
ipaddr, port = sock.getsockname()
broadcast((ipaddr, port))
cluster_spec = aggregate_spec()
os.environ["TF_CONFIG"] = json.dumps({
"cluster": cluster_spec,
"task": {"type": …, "index": …}
})
server = tf.train.Server(cluster_spec, task_index=...)
tf.estimator.train_and_evaluate(…)
broadcastwill use Skein’s kv store to send allocated (host, port) pairs via an init event. Each container will stop on aggregate_spec method to wait for all init events with (host, port) pairs from all containers. Once it has received all of them it constructs the ClusterSpec, starts the TensorFlow server and starts learning.
tf-yarn API’s
tf-yarn comes with two API’s to launch a training— run_on_yarn and standalone_client_mode.
run_on_yarn
The only abstraction tf-yarn adds on top of the ones already present in
TensorFlow is experiment_fn. It is a function returning a triple of oneEstimator and two specs — TrainSpec and EvalSpec.
Here is a stripped down experiment_fn from one of the provided examples to give an idea of what it might look like:
from tf_yarn import Experiment
def experiment_fn():
# …
estimator = tf.estimator.DNNClassifier(…)
return Experiment(
estimator,
tf.estimator.TrainSpec(train_input_fn, max_steps=…),
tf.estimator.EvalSpec(eval_input_fn)
)
An experiment can be scheduled on YARN using the run_on_yarn function which takes three required arguments:
pyenv_zip_pathwhich contains the tf-yarn modules and dependencies like TensorFlow to be shipped to the cluster.pyenv_zip_pathcan be generated easily with a helper function based on the current installed virtual environment;experiment_fnas described above;task_specsdictionary specifying how much resources to allocate for each of the distributed TensorFlow task type.
The example uses the Wine Quality dataset from UCI ML repository. With just under 5000 training instances available, there is no need for multi-node training, meaning that a chief complemented by an evaluator would manage just fine. Note that each task will be executed in its own YARN container.
from tf_yarn import packaging, run_on_yarn, TaskSpec
pyenv_zip_path, _ = packaging.upload_env_to_hdfs()
run_on_yarn(
pyenv_zip_path,
experiment_fn,
task_specs={
"chief": TaskSpec(memory=2 * 2**10, vcores=4),
"evaluator": TaskSpec(memory=2**10, vcores=1)
}
)
Under the hood, the experiment function is shipped to each container, evaluated and then passed to the train_and_evaluate function.
experiment = experiment_fn()
tf.estimator.train_and_evaluate(
experiment.estimator,
experiment.train_spec,
experiment.eval_spec
)
standalone_client_mode
Standalone client mode keeps most of the previous concepts. Instead of calling train_and_evaluate on each worker, one just spawns the TensorFlow server on each worker and then locally runs train_and_evaluate on the client. TensorFlow will take care of sending the graph to each worker. This removes the burden of having to ship manually the experiment function to the containers.
Here is the previous example in Standalone client mode:
from tensorflow.contrib.distribute import DistributeConfig, ParameterServerStrategy
from tf_yarn import standalone_client_mode, TaskSpec
with standalone_client_mode(
task_specs={
"worker": TaskSpec(memory=4 * 2**10, vcores=4, instances=2),
"ps": TaskSpec(memory=4 * 2**10, vcores=4, instances=1)
}) as cluster_spec:
distrib_config = DistributeConfig(
train_distribute=ParameterServerStrategy(),
remote_cluster=cluster_spec
)
estimator = tf.estimator.DNNClassifier(
...
config=tf.estimator.RunConfig(
experimental_distribute=distrib_config
)
)
tf.estimator.train_and_evaluate(
estimator,
tf.estimator.TrainSpec(...),
tf.estimator.EvalSpec(...))
standalone_client_mode takes care of creating the ClusterSpec as described before. We activate ParameterServerStrategy in the RunConfig and then call train_and_evaluate.
In addition to training estimators, Standalone client mode also gives access to TensorFlow’s low-level API. Have a look at the examples for more information.
You might think that having this mode available, why not deprecating the other run_on_yarn mode? It looks easier and there is no need to ship the experiment_fn anymore. The reason is simple: Standalone client mode is actually still an experimental feature and certain use cases are not yet supported.
Error reporting
Having the system setup is one thing but unfortunately not the end. In case of a problem, debugging YARN applications could be a tedious task. A common workflow following a failure is to fetch the logs for the application on each worker and manually search for exceptions or any other error in the output of each container. Clearly, this approach does not scale well. Imagine debugging a training with 100 workers!
tf-yarn improves the situation by pretty-printing the stack traces of the failed tasks after the application finishes.
INFO:tf_yarn:
queue: dev
start_time: 2019–04–19 12:50:51.985000+00:00
finish_time: 2019–04–19 12:52:19.840000+00:00
final_status: FAILED
tracking_url: […]
user: ..
INFO:tf_yarn:
chief:0 24–8a-07-df-57-b0:34360 SUCCEEDED
evaluator:0 7c-fe-90-a5-e2–30:43249 FAILED
Exception in task evaluator:0:
Traceback (most recent call last):
[…]
File “linear_classifier_experiment.py”, line 25, in eval_input_fn
RuntimeError: […]
Interesting issues
The API of tf-yarn now looks quite simple and easy but the devil, as it often happens, is in the details. For the more advanced readers, we will briefly describe the main challenges we have encountered during the development of tf-yarn as well as the implemented solutions.
Port reservation race condition
YARN does not allow the application to reserve a range of TCP ports on each node prior to starting it. This means that every YARN application has to implement port reservation manually. Typically, this is done by creating a TCP socket and binding it to port 0 which instructs the operating system to allocate an available ephemeral port. The port would then remain reserved as long as the socket is open.
In distributed TensorFlow, tasks communicate with each other via an instance of the tf.train.Server. The public API of tf.train.Server is fairly minimal. Specifically, it does not offer any way to attach a server to an existing TCP socket. Therefore, in order to start a server one has to first allocate an ephemeral port, close the socket bound to it, and then create a tf.train.Server listening on the same port.
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.bind(("", 0))
ipaddr, port = sock.getsockname()
broadcast((ipaddr, port))
cluster_spec = aggregate_spec()
# other process can steal socket here
server = tf.train.Server(cluster_spec)
During the interval between closing the socket and re-binding a tf.train.Server, there is a possibility of hijacking the port by another TensorFlow training running on the same node.
What can be done about this?
First, we should keep the interval in which this can happen as small as possible. In our first implementation, we were waiting for the estimator object to be initialized, which can take several seconds, and as a consequence was increasing the probability of port hijacking. Once fixed, the time frame is small enough.
An even better solution would be if tf.train.Server could set the SO_REUSEPORT option on the TCP socket before binding it to an address. This would allow tf-yarn to keep the port reserved for the whole lifetime of a task, eliminating the possibility for a race condition and tf.train.Server just reusing the same port again. See relevant issue in the TensorFlow issue tracker which hasn’t been moved further because the previous fix is good enough for our use cases.
Accessing HDFS in TensorFlow
TensorFlow implements its own I/O subsystem called tf.gfile allowing to access files in a unified way on a number of file systems including HDFS. The HDFS access itself is done via libhdfs — a native library wrapping the Java HDFS client. Being a Java library under the hood, libhdfs relies on a number of environment variables to be set, most notably CLASSPATH which must include the full Hadoop distribution.
The CLASSPATHvalue on the containers is controlled by the yarn.application.classpath setting which defaults to:
$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, […]
The wildcard symbol (`*`) is understood by the JVM and is expanded to a list of JARs located in the corresponding directory. If the JVM has been invoked via JNI, wildcard processing does not happen, and classpath entries containing wildcards are ignored leading to class lookup failures in libhdfs API calls. The fix is, of course, to expand all the wildcards manually prior to calling libhdfs as explained in the relevant section of the TensorFlow documentation. This is exactly what has been implemented in tf-yarn. In the current version of tf-yarn we removed wildcard expansion in Python code and opted for directly patching libhdfs in our Hadoop branch to use an environment variable with all wildcards expanded.
Mixed CPU/GPU training
Hadoop 2.6.X does not support GPU as a first-class scheduling resource.
A common workaround is to use node labels where CPU-only nodes are kept unlabelled, while GPU-enabled ones have a label. In order to isolate the two types of workloads, GPU nodes are typically bound to a separate queue which is different from the default one.
Currently, tf-yarn assumes that the GPU label is gpu. There is no
prescription on the name of the queue with GPU nodes, however, for the example we will use the name ml-gpu.
The default behaviour of tf-yarn is to run on CPU-only nodes. In order
to run on the GPU, one needs to:
- Set the
queueargument in function call torun_on_yarn - Set
TaskSpec.labeltoNodeLable.GPUfor relevant task types.
A good rule of a thumb is to run compute heavychiefandworker
tasks on GPU, while keepingpsandevaluatoron CPU. - Create two dedicated packages to ship to the containers (TensorFlow comes with two different packages for CPU & GPU support —
tensorflow&tensorflow-gpu)
from tf_yarn import NodeLabel
run_on_yarn(
{
NodeLabel.GPU: my_gpu_package,
NodeLabel.CPU: my_cpu_package
},
experiment_fn,
task_specs={
"chief": TaskSpec(memory=2 * 2**10, vcores=4, label=NodeLabel.GPU),
"evaluator": TaskSpec(memory=2**10, vcores=1)
},
queue=”ml-gpu”
)
Too many skein drivers
We use tf-yarn for hyper-parameter tuning of our TensorFlow models, running multiple learnings with different parameters in parallel.
Skein uses a background Java process (called driver) to do the communication with YARN. By default, each application will create a new driver spawning a new JVM each time. This doesn’t scale when running hundreds of learnings in parallel on one machine.
In our case, we had a specific configuration on a shared gateway and were running out of threads. The parallel GC on Java 8 will create 5/8 threads by available cores on the machine. Being limited to 1024 threads per user on a machine with 72 cores, we were quickly running out of threads.
We improved the situation by tuning the allocations of the Skein Java driver in particular by reducing the number of threads for the GC — XX:ParallelGCThreads=1. Thanks to this fix in Skein, we can now create one single Skein client and use it in multiprocessing scenarios:
import concurrent
import skein
def learn(experiment_fn, client):
run_on_yarn(
pyenv_zip_path,
experiment_fn,
task_specs={
...
},
skein_client=client
)
with skein.Client() as client:
with concurrent.futures.ProcessPoolExecutor() as executor:
[executor.submit(learn, experiment_fn, client) for i in range(10)]
Conclusion
In this post, we presented how to run distributed TensorFlow on a Hadoop cluster with tf-yarn, why we think that running TensorFlow on Spark is the wrong approach and how we designed our own full Python-based library for running TensorFlow on YARN.
The issues we encountered may give some insights for people working with TensorFlow and Hadoop.
Want to learn more on the topic? Criteo is hiring.
Thanks to all contributors of tf-yarn: Sergei Lebedev, Gaetan Racic, Jean Denis Lesage, Martin Felipe Perez-Guevara Truskowski, Remy Saissy, Nicolas Fraison, Akim Boyko, Fanny Riols, Marc Tchiboukdijan, Olivier Toromanoff.
Author: Fabian Horing, Criteo AI Lab